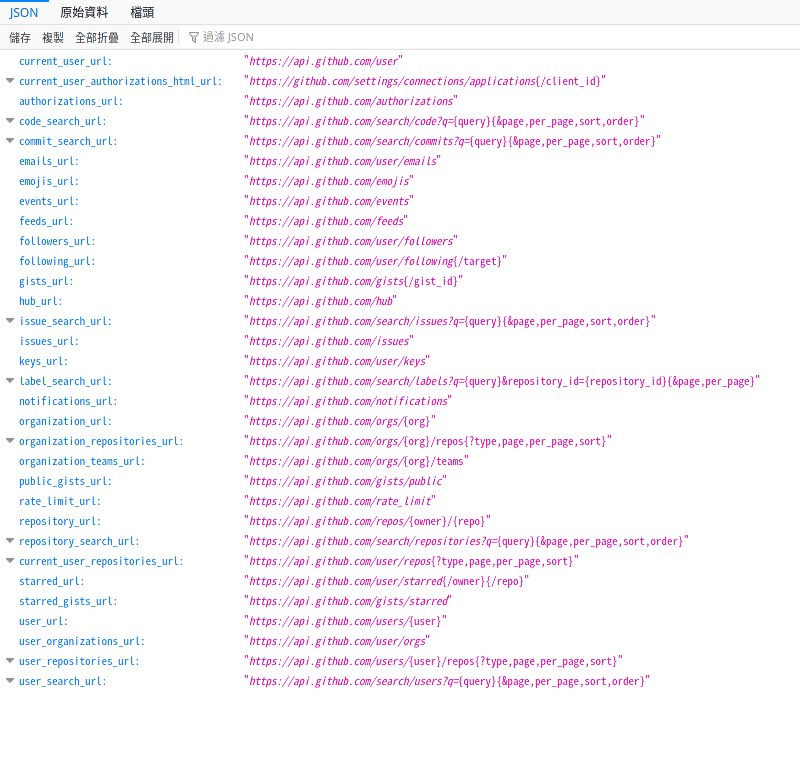
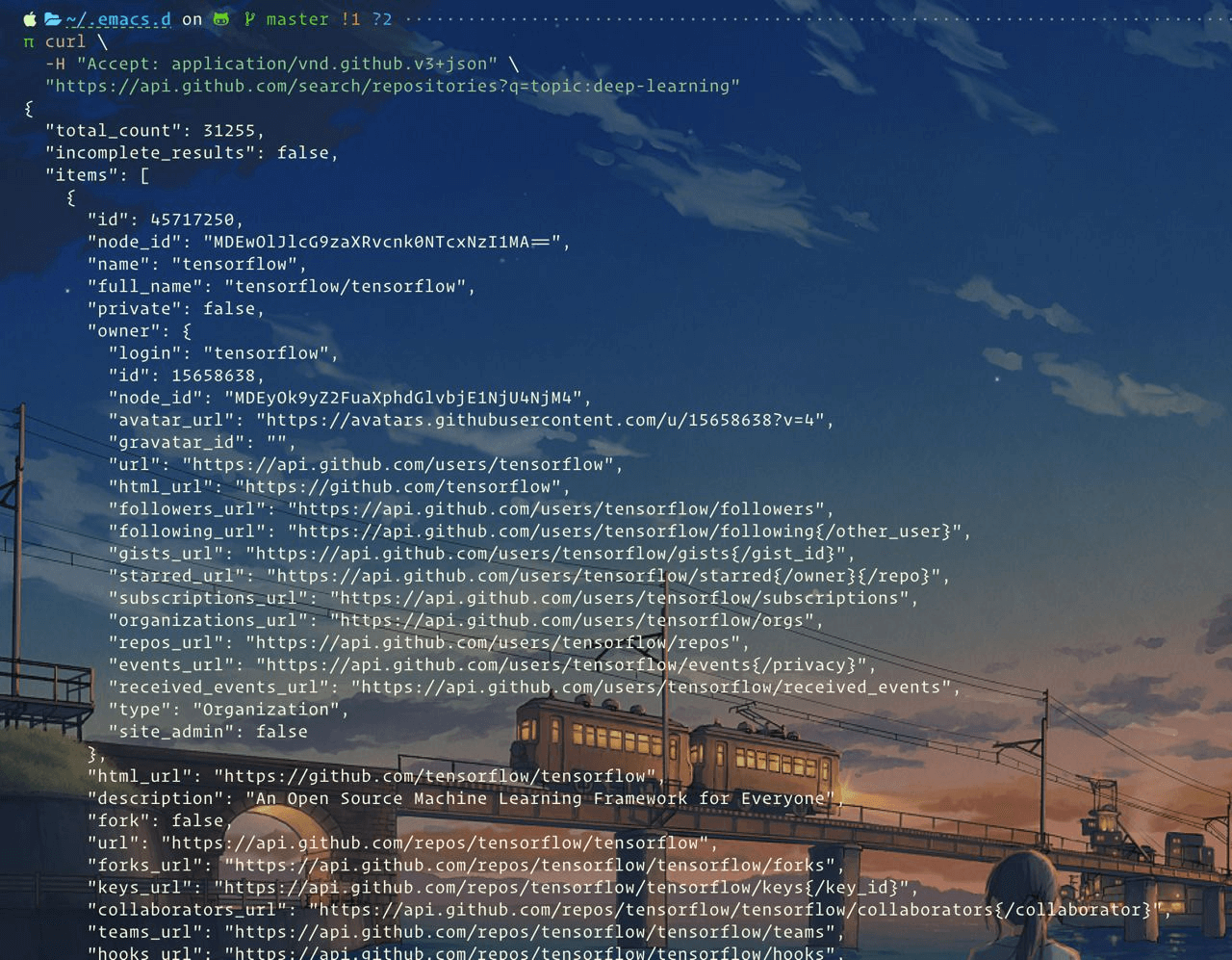
start_urls=[]# save urlsbase_url="https://github.com/topics/deep-learning?page="allowed_domains="https://github.com"print("\n------------start grabbing all urls--------------------------\n")foriinrange(1,35):try:html=requests.get(base_url+str(i),headers=headers_raw_page,proxies=proxies,timeout=timeoutSec)exceptExceptionase:print(e)print('fail to get request from ip via proxy')soup=BeautifulSoup(html.text,"html.parser")# print(soup.prettify())# urls = soup.find_all("a", {'class': 'text-bold'})forjinsoup.find_all("a",{'class':'text-bold'}):start_urls.append(allowed_domains+j['href'])print(allowed_domains+j['href'])time.sleep(1.5)
print(start_urls)print("The data length: ",len(start_urls),"\n")result=[]labels=['name','star','commits','fork','issues','pull_requests','branches','tags']print("\n------------start grabbing data--------------------------\n")time.sleep(1.5)i=1forurlinstart_urls:try:html=requests.get(url,headers=headers,proxies=proxies,timeout=timeoutSec)exceptExceptionase:print(e)print('fail to get request from ip via proxy')# print(html)soup=BeautifulSoup(html.text,"html.parser")# star = soup.findall("a", text="starred")# print(soup.prettify())item={}item['name']=urlprint("all: ",len(start_urls),"index ",i,", start: ",item['name'])i+=1num=soup.find_all("a",{'class':'social-count'})# print(num)# print('\n')item['star']=num[0]item['fork']=num[1]num=soup.find_all("span",{'class':'d-none d-sm-inline'})# print('\n')# print(num)if(len(num)==2):item['commits']=num[1]else:item['commits']=num[0]num=soup.find_all("span",{'class':'Counter'})# print('\n')# print(num)item['issues']=num[1]item['pull_requests']=num[2]# item['contributors'] = num[7]# item['projects'] = num[4]# item['security'] = num[5]num=soup.find_all("a",{'class':'Link--primary no-underline'})# print('\n')# print(num)item['branches']=num[0]# item['release'] = num[1]# item['used_by'] = num[3]# num = soup.find_all("span", {'class': 'Counter'})# item['contributors'] = num[4]num=soup.find_all("a",{'class':'ml-3 Link--primary no-underline'})# print('\n')# print(num)item['tags']=num[0]print("end",item['name'],"\n")# print("\n", item['commits'])result.append(item)time.sleep(1.5)
存成 CSV
我們接下來根據 labels 去存成 CSV 文件。
1
2
3
4
5
6
7
8
9
10
11
print("\n------------start saving data as csv--------------------------\n")try:withopen('csv_dct.csv','w')asf:writer=csv.DictWriter(f,fieldnames=labels)writer.writeheader()foreleminresult:writer.writerow(elem)print("save success")exceptIOError:print("I/O error")
classgithub_grab(object):# ...defget_all_repositories(self):print("\n------------start grabbing all repositories--------------------------\n")index=1forurlinself.base_url:print("\nbase url : "+url+"\n")foriinrange(1,5):try:req=requests.get(url+"&page="+str(i)+"&per_page=100",headers=headers,proxies=proxies,timeout=timeoutSec)if(req.status_code==403):print("Rate limit, sleep 60 sec")time.sleep(60)i-=1continueelif(req.status_code==404orreq.status_code==204):print('The source is not found')continueitems=req.json()['items']# temp = json.loads(req)# print(type(req))print("req len "+str(len(items)))self.repositories+=itemsprint('grab page '+str(index)+', current repository quantity : '+str(len(self.repositories)))index+=1# print(self.repositories)exceptExceptionase:print(e)print('fail to get request from ip via proxy')# sleep# time.sleep(2)
classgithub_grab(object):# ...defget_repository_readme(self,url):print("start to get "+url+" readme")try:req=requests.get("https://github.com/"+url+"/blob/master/README.md",headers=headers_raw_page,proxies=proxies,timeout=timeoutSec)if(req.status_code==403):print("Rate limit, sleep 60 sec")time.sleep(60)req=requests.get("https://github.com/"+url+"/blob/master/README.md",headers=headers_raw_page,proxies=proxies,timeout=timeoutSec)elif(req.status_code==404orreq.status_code==204):print('The source is not found')# print(type(req))soup=BeautifulSoup(req.text.replace('\n',''),"html.parser")num=soup.find_all("div",{'id':'readme'})# print(req)# print("req len " + str(len(req)))# time.sleep(2)returnnum[0]iflen(num)>=1else""exceptExceptionase:print(e)print('fail to get request from ip via proxy')
classgithub_grab(object):# ...defget_repository_commits(self,commits_temp):print("start to get "+commits_temp['name']+" commits\' data")try:foriinrange(1,100000):req=requests.get("https://api.github.com/repos/"+commits_temp['name']+"/commits?per_page=100&page="+str(i),headers=headers,proxies=proxies,timeout=timeoutSec)if(req.status_code==403):print("Rate limit, sleep 60 sec")time.sleep(60)i-=1continueelif(req.status_code==404orreq.status_code==204):print('The source is not found')continue# print("commits times" + str(i))items=req.json()# if no dataiflen(items)==0:break# if the time is too olderif(items[0]['commit']['author']['date']<"2020-03-01T00:00:00Z"):breakif(items[-1]['commit']['author']['date']>"2021-04-01T00:00:00Z"):continuefordate_timeinitems:if(date_time['commit']['author']['date']<"2020-03-01T00:00:00Z"):breakcommits_temp=self.date_classify(commits_temp,date_time['commit']['author']['date'])# time.sleep(2)returncommits_tempexceptExceptionase:print(e)print('fail to get request from ip via proxy')
classgithub_grab(object):# ...defget_repository_pull_requests(self,pr_temp):print("start to get "+pr_temp['name']+" pull requests\' data")try:foriinrange(1,100000):req=requests.get("https://api.github.com/repos/"+pr_temp['name']+"/pulls?per_page=100&page="+str(i),headers=headers,proxies=proxies,timeout=timeoutSec)if(req.status_code==403):print("Rate limit, sleep 60 sec")time.sleep(60)i-=1continueelif(req.status_code==404orreq.status_code==204):print('The source is not found')continueitems=req.json()# if no dataiflen(items)==0:break# if the time is too olderif(items[0]['created_at']<"2020-03-01T00:00:00Z"):breakif(items[-1]['created_at']>"2021-04-01T00:00:00Z"):continuefordate_timeinitems:# print(date_time['created_at'])if(date_time['created_at']<"2020-03-01T00:00:00Z"):breakpr_temp=self.date_classify(pr_temp,date_time['created_at'])# time.sleep(2)returnpr_tempexceptExceptionase:print(e)print('fail to get request from ip via proxy')
classgithub_grab(object):# ...defget_repository_forks(self,forks_temp):print("start to get "+forks_temp['name']+" forks\' data")try:foriinrange(1,100000):req=requests.get("https://api.github.com/repos/"+forks_temp['name']+"/forks?per_page=100&page="+str(i),headers=headers,proxies=proxies,timeout=timeoutSec)if(req.status_code==403):print("Rate limit, sleep 60 sec")time.sleep(60)i-=1continueelif(req.status_code==404orreq.status_code==204):print('The source is not found')continueitems=req.json()# print("forks times" + str(i))# if no dataiflen(items)==0:break# if the time is too olderif(items[0]['created_at']<"2020-03-01T00:00:00Z"):breakif(items[-1]['created_at']>"2021-04-01T00:00:00Z"):continuefordate_timeinitems:# print(date_time['created_at'])if(date_time['created_at']<"2020-03-01T00:00:00Z"):breakforks_temp=self.date_classify(forks_temp,date_time['created_at'])# time.sleep(2)returnforks_tempexceptExceptionase:print(e)print('fail to get request from ip via proxy')
classgithub_grab(object):# ...defget_repository_issues(self,issues_temp):print("start to get "+issues_temp['name']+" issues\' data")try:foriinrange(1,100000):req=requests.get("https://api.github.com/repos/"+issues_temp['name']+"/issues/events?per_page=100&page="+str(i),headers=headers,proxies=proxies,timeout=timeoutSec)if(req.status_code==403):print("Rate limit, sleep 60 sec")time.sleep(60)i-=1continueelif(req.status_code==404orreq.status_code==204):print('The source is not found')continueitems=req.json()# if no dataiflen(items)==0:break# if the time is too olderif(items[0]['created_at']<"2020-03-01T00:00:00Z"):breakif(items[-1]['created_at']>"2021-04-01T00:00:00Z"):continuefordate_timeinitems:# print(date_time['created_at'])if(date_time['created_at']<"2020-03-01T00:00:00Z"):breakissues_temp=self.date_classify(issues_temp,date_time['created_at'])# time.sleep(2)returnissues_tempexceptExceptionase:print(e)print('fail to get request from ip via proxy')
 Rem Blog
Rem Blog