Python 爬蟲實戰教學 - Github 倉庫特徵爬取

前言
因為這期學期上半我選了機器學習與數據挖掘,我在課程小組項目中負責了爬蟲這個部份,我會在這篇文章紀錄一下我的過程,並教導大家如何實戰 Python 爬蟲。
項目說明
我們這個小組項目的爬取需求是爬取 Github 項目的各個特徵,這篇文章會分兩個部份,第一個部份是使用 BeautifulSoup 爬取原生的 HTML 頁面,第二部份是使用 Github API,其中第二部份包含了每個倉庫的 Commits、pull_request 等月變化量(2020.03 ~2021.03)。
P.S. 其實是我在剛開始寫爬蟲的時候,覺得 GIthub API 回傳的數據特徵有點少,所以就直接爬 Github 原生 HTML 頁面,沒有去爬月變化的數據,結果組長說要我重新去寫爬蟲,要爬月變化數據。
開發前準備
安裝相關庫
因為我們需要使用到的庫有 BeautifulSoup 和 requests 等。所以有些需要自己去安裝,
import requests
import time
import csv
import json
from bs4 import BeautifulSouppip install requests BeautifulSoupGithub 私人 Token
因為我們需要爬取 Github 的網頁和使用 Github API,我們需要申請 Personal token,避免我們的請求達到 Rate Limit,Github 有限制一分鐘內的請求次數。

請求設定
我們請求在請求頁面時需要模仿瀏覽器的請求方式
如果自己沒有 proxies 可以去掉這一項。
# request settings
# token
token = ''
# proxy
proxies = {
"http": "http://127.0.0.1:7890",
"https": "http://127.0.0.1:7890",
}
# through Github api
headers = {
'Accept': 'application/vnd.github.v3+json',
'Authorization': 'token {token}'.format(token = token)
}
# 模仿瀏覽器請求原生頁面
headers_raw_page = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:89.0) Gecko/20100101 Firefox/89.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8',
'Authorization': 'token {token}'.format(token = token)
}
timeoutSec = 15 # setup your timeout spec(sec)第一部份 - 原生頁面
確定爬取規則
先確定要爬的數據,我們預先在 Github topic 中爬取 deep-learning 的相關 Repositories 的 URL 作為我們數據分析的數據量。並且觀察頁面的請求與分頁。
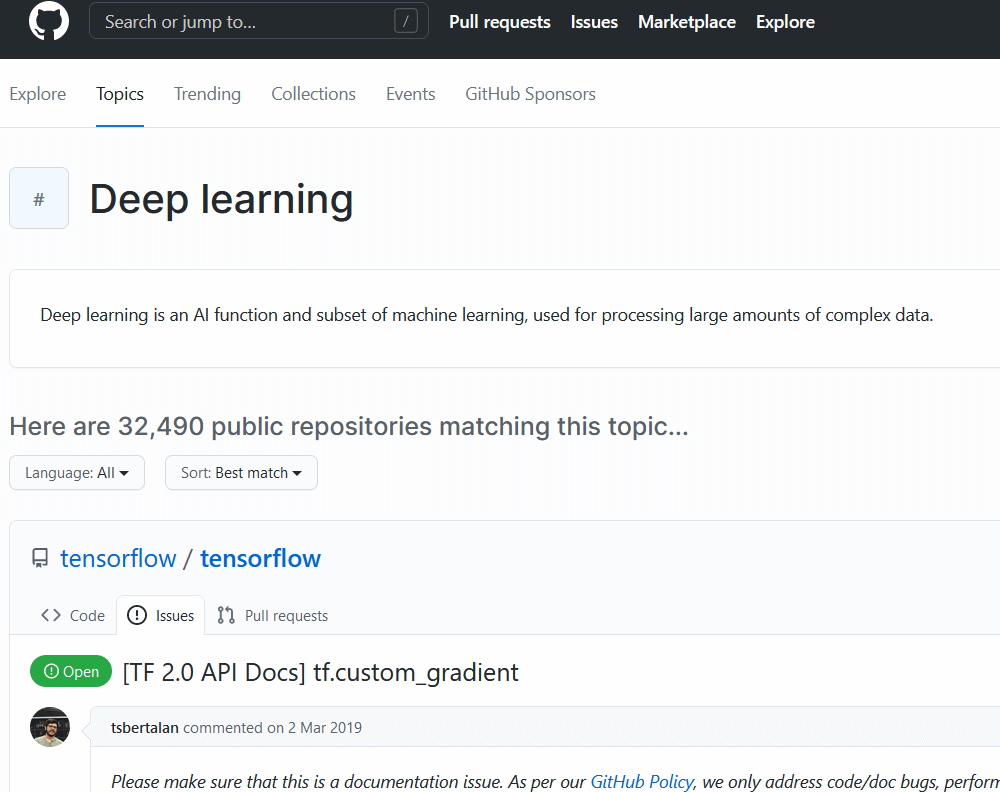
我們可以按下 F12 可以在網路請求部份找到我們頁面請求的內容,並且在傳參部份找的到 page 參數,page 參數以及 per_page 參數可以作為我們循環請求的依據。
per_page 參數是決定每頁顯示多少列倉庫,這部份是我在看完 Github API 後知道的參數。

爬取我們要的所有倉庫
下面是使用迴圈去調參,接著使用 BS4 去解析頁面元素。爬取的內容會存到 start_urls。
start_urls = [] # save urls
base_url = "https://github.com/topics/deep-learning?page="
allowed_domains = "https://github.com"
print("\n------------start grabbing all urls--------------------------\n")
for i in range(1, 35):
try:
html = requests.get(base_url+str(i), headers=headers_raw_page, proxies=proxies, timeout= timeoutSec)
except Exception as e:
print(e)
print('fail to get request from ip via proxy')
soup = BeautifulSoup(html.text, "html.parser")
# print(soup.prettify())
# urls = soup.find_all("a", {'class': 'text-bold'})
for j in soup.find_all("a", {'class': 'text-bold'}):
start_urls.append(allowed_domains + j['href'])
print(allowed_domains + j['href'])
time.sleep(1.5)細爬每個倉庫特徵
由於我們一開始爬的倉庫特徵並不是很夠,我們需要去細爬我們每個倉庫的更多數據特徵,接著我們根據 start_url 存的內容去爬取需要的倉庫細節。

print(start_urls)
print("The data length: ", len(start_urls), "\n")
result = []
labels = ['name', 'star', 'commits', 'fork', 'issues', 'pull_requests',
'branches', 'tags']
print("\n------------start grabbing data--------------------------\n")
time.sleep(1.5)
i = 1
for url in start_urls:
try:
html = requests.get(url, headers=headers, proxies=proxies, timeout= timeoutSec)
except Exception as e:
print(e)
print('fail to get request from ip via proxy')
# print(html)
soup = BeautifulSoup(html.text, "html.parser")
# star = soup.findall("a", text="starred")
# print(soup.prettify())
item = {}
item['name'] = url
print("all: ", len(start_urls), "index ", i, ", start: ", item['name'])
i+=1
num = soup.find_all("a", {'class': 'social-count'})
# print(num)
# print('\n')
item['star'] = num[0]
item['fork'] = num[1]
num = soup.find_all("span", {'class': 'd-none d-sm-inline'})
# print('\n')
# print(num)
if(len(num) == 2):
item['commits'] = num[1]
else:
item['commits'] = num[0]
num = soup.find_all("span", {'class': 'Counter'})
# print('\n')
# print(num)
item['issues'] = num[1]
item['pull_requests'] = num[2]
# item['contributors'] = num[7]
# item['projects'] = num[4]
# item['security'] = num[5]
num = soup.find_all("a", {'class': 'Link--primary no-underline'})
# print('\n')
# print(num)
item['branches'] = num[0]
# item['release'] = num[1]
# item['used_by'] = num[3]
# num = soup.find_all("span", {'class': 'Counter'})
# item['contributors'] = num[4]
num = soup.find_all("a", {'class': 'ml-3 Link--primary no-underline'})
# print('\n')
# print(num)
item['tags'] = num[0]
print("end", item['name'], "\n")
# print("\n", item['commits'])
result.append(item)
time.sleep(1.5)存成 CSV
我們接下來根據 labels 去存成 CSV 文件。
print("\n------------start saving data as csv--------------------------\n")
try:
with open('csv_dct.csv', 'w') as f:
writer = csv.DictWriter(f, fieldnames=labels)
writer.writeheader()
for elem in result:
writer.writerow(elem)
print("save success")
except IOError:
print("I/O error")第二部份 - Github API
確定爬取需求
我們需要的是各語言的熱門 repository,每個倉庫的最終 name、language、stargzers、forks、open_issues、watchers、readme,以按照月份變化(2020.03 ~2021.03)的 commits、pull requests、forks、issues events。
為了求方便 我們需要使用 GIthub 提供的 API 進行爬取,然而 Readme 部分需要去爬取原生的 HTML 頁面。
確定爬取後需要分成三張表,基本數據 gitub_basic.csv;月變化數據 github_commits.csv、github_pull_requests.csv。(後面因為 forks 和 issues 的樂變化數據爬取過多,拖長每個 repo 的數據處理進度,導致平均一個 repo 需要爬取 8 mins 左右,所以棄掉這兩項月變化數據)
先查看 Github API
我們先查看 Github 提供的 API 文檔。
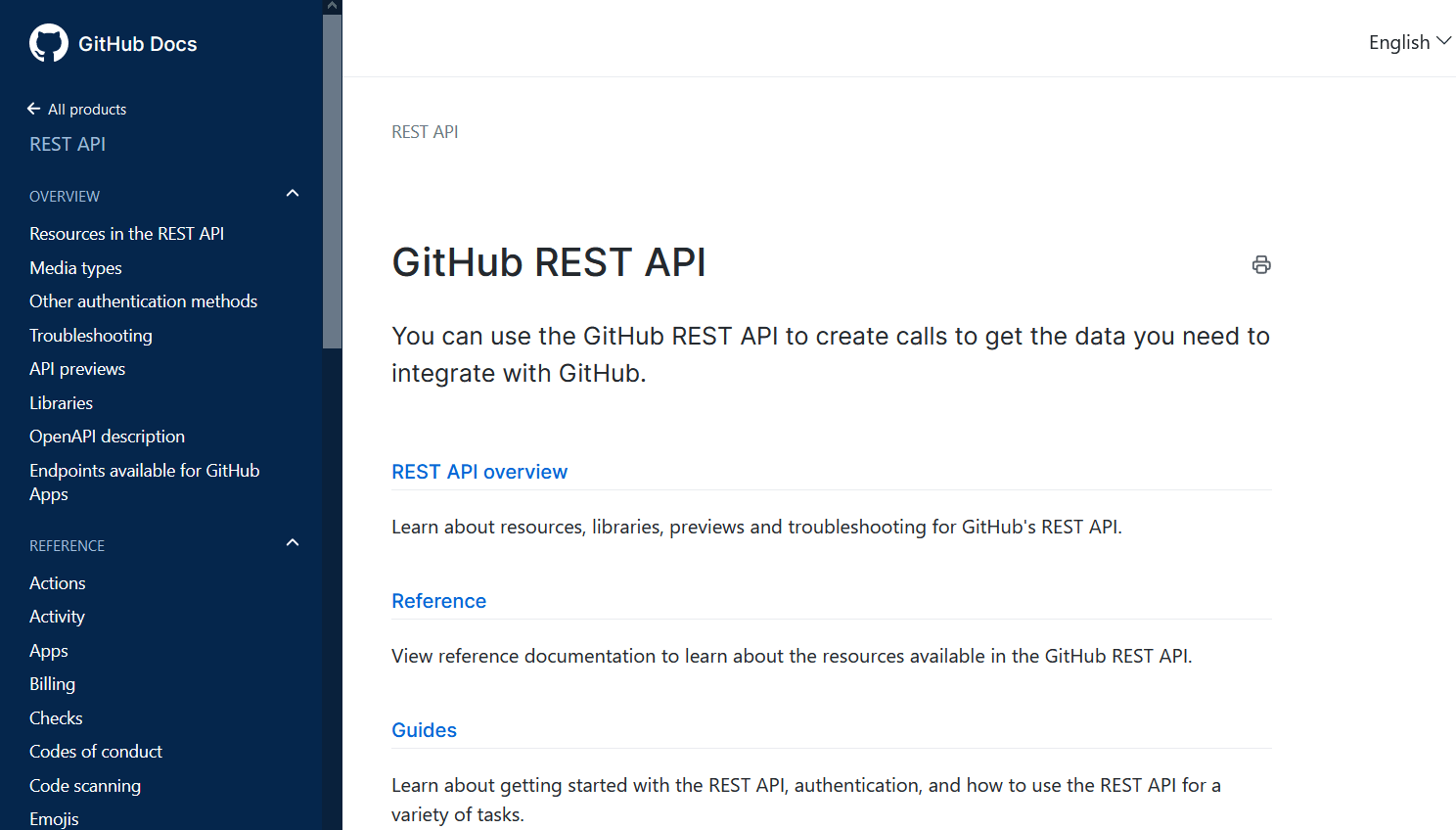
我們首先需要用到的 API 是 Search 裡面的 https://api.github.com/search/repositories。
我們先測試一下 API:
你也可以使用 Postman 去做測試,因為有時回傳值太長了,終端機直接砍掉前面部份。
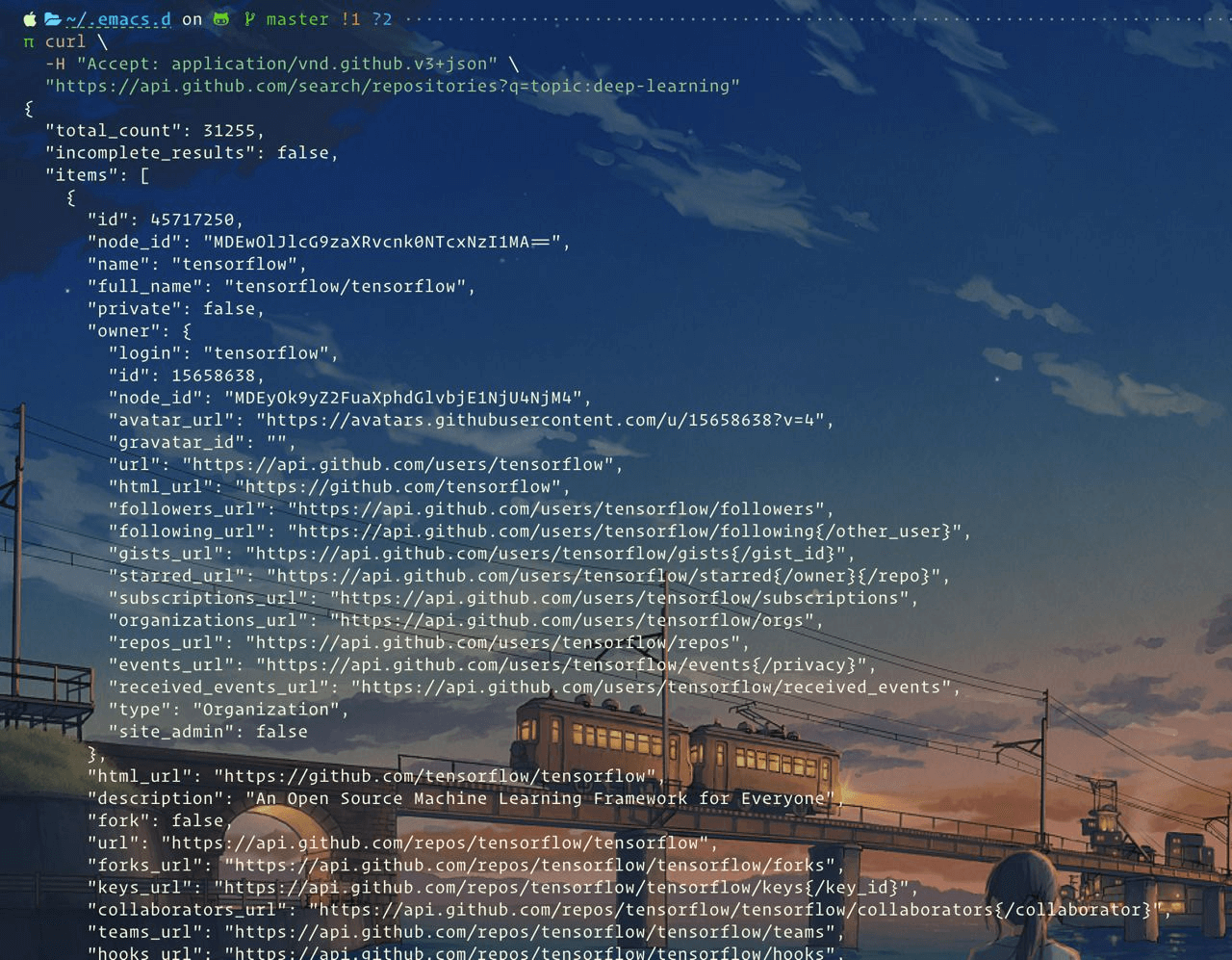
確定特徵
因為我們使用 Github API 回傳的數據特徵已經有
- name
- language
- stargazers
- forks
- open_issues
- watchers
以及各種請求 URL(作為後面爬取各),雖然特徵沒有第一部份爬取 HTML 頁面的數據特徵多,但作為數據分析特徵夠了。
編寫爬取類
編寫爬蟲類的成員變量,與構造函數。並且使用 Github search repositories 的 API 分別,總共的語言有 python、java、golang、js。
其中
- repositories: 爬取的 repo
- basic_table: repo 的基本特徵
- commits_table: 每個 repo 的 commits 月變化數據
- pull_requests_table: 每個 repo 的 pull requests月變化數據
- forks_table: 每個 repo 的 forks月變化數據
- issues_table: 每個 repo 的 issues月變化數據
- basic_url: 根據爬取語言熱門 repos 的爬取 api
- basic_labels: basic_table 存成 csv 文件的標籤
- template_labels: 月變化數據存成 csv 文件的標籤
- template_table: 月變化數據初始化賦值模板
class github_grab(object):
def __init__(self):
self.repositories = []
self.basic_table = []
self.commits_table = []
self.pull_requests_table = []
self.forks_table = []
self.issues_table = []
self.base_url = [
"https://api.github.com/search/repositories?q=language:python&sort=stars",
"https://api.github.com/search/repositories?q=language:java&sort=stars",
"https://api.github.com/search/repositories?q=language:c&sort=stars",
"https://api.github.com/search/repositories?q=language:golang&sort=stars",
"https://api.github.com/search/repositories?q=language:js&sort=stars"
]
self.basic_labels = [
'name', 'language', 'stargazers' , 'forks', 'open_issues', 'watchers', 'readme'
]
# commits pull_requests forks issues_events
self.template_labels = [
'name',
'2019_01', '2019_02', '2019_03', '2019_04',
'2019_05', '2019_06', '2019_07', '2019_08',
'2019_09', '2019_10', '2019_11', '2019_12',
'2020_01', '2020_02', '2020_03', '2020_04',
'2020_05', '2020_06', '2020_07', '2020_08',
'2020_09', '2020_10', '2020_11', '2020_12',
'2021_01', '2021_02', '2021_03'
]
self.template_table = {
'name': '',
'2020_03': 0, '2020_04': 0, '2020_05': 0, '2020_06': 0,
'2020_07': 0, '2020_08': 0, '2020_09': 0, '2020_10': 0,
'2020_11': 0, '2020_12': 0, '2021_01': 0, '2021_02': 0,
'2021_03': 0
}爬取我們需要的所有熱門倉庫
根據爬取類的 baseURL 遍歷請求,由於怕數據量太大,爬取過久,所以我們每個語言的熱門倉庫只爬取 40 個,總共會爬取 200 個倉庫。每次請求都需要設定如果爬取回來的狀態碼如果是 403,則需要等待 1 分鐘繼續爬取,如果是 404 或是 204 則代表資源不存在。
class github_grab(object):
# ...
def get_all_repositories(self):
print("\n------------start grabbing all repositories--------------------------\n")
index = 1
for url in self.base_url:
print("\nbase url : " + url + "\n")
for i in range(1, 5):
try:
req = requests.get(url + "&page=" + str(i) + "&per_page=100",
headers=headers, proxies=proxies, timeout=timeoutSec)
if(req.status_code == 403):
print("Rate limit, sleep 60 sec")
time.sleep(60)
i -= 1
continue
elif(req.status_code == 404 or req.status_code == 204):
print('The source is not found')
continue
items = req.json()['items']
# temp = json.loads(req)
# print(type(req))
print("req len " + str(len(items)))
self.repositories += items
print('grab page ' + str(index) +
', current repository quantity : ' + str(len(self.repositories)))
index += 1
# print(self.repositories)
except Exception as e:
print(e)
print('fail to get request from ip via proxy')
# sleep
# time.sleep(2)編寫 Readme 爬取方法
由於每個倉庫的 readme 的文件名都不一樣,所以我只要以文件名是 readme 或 README,文件類型是 *.md 或 *.rst,如果還有其它的命名方式,我們可以認為該倉庫的文件命名不規範,不需加入考量。這裡的爬取使用 BS4。
class github_grab(object):
# ...
def get_repository_readme(self, url):
print("start to get " + url + " readme")
try:
req = requests.get("https://github.com/" + url + "/blob/master/README.md",
headers=headers_raw_page, proxies=proxies, timeout=timeoutSec)
if(req.status_code == 403):
print("Rate limit, sleep 60 sec")
time.sleep(60)
req = requests.get("https://github.com/" + url + "/blob/master/README.md",
headers=headers_raw_page, proxies=proxies, timeout=timeoutSec)
elif(req.status_code == 404 or req.status_code == 204):
print('The source is not found')
# print(type(req))
soup = BeautifulSoup(req.text.replace('\n', ''), "html.parser")
num = soup.find_all("div", {'id': 'readme'})
# print(req)
# print("req len " + str(len(req)))
# time.sleep(2)
return num[0] if len(num) >= 1 else ""
except Exception as e:
print(e)
print('fail to get request from ip via proxy')編寫處理所有的 repo 方法
由於我們在前面在 get_all_repositories 類方法已經將很多基本數據爬下來,所以我們 basic 部分不需要進一步爬取,月變化數據需要另外寫類方法處理。
class github_grab(object):
# ...
def deal_with_repositories(self):
print("-------------------start to deal with repo\'s data----------------------\n")
i = 1
for repo in self.repositories:
print('deal with the ' + str(i) + ' / ' +
str(len(self.repositories)) + " " + repo['full_name'])
i += 1
# basic_table
basic_temp = {}
basic_temp['name'] = repo['full_name']
basic_temp['stargazers'] = repo['stargazers_count']
basic_temp['watchers'] = repo['watchers_count']
basic_temp['language'] = repo['language']
basic_temp['forks'] = repo['forks_count']
basic_temp['open_issues'] = repo['open_issues']
basic_temp['readme'] = self.get_repository_readme(
repo['full_name'])
self.basic_table.append(basic_temp)
# commits_table
# init use copy
temp = self.template_table.copy()
# print('init temp')
# print(temp)
temp['name'] = repo['full_name']
temp = self.get_repository_commits(temp)
# print(temp)
self.commits_table.append(temp)
# print("-----")
# print(self.commits_table)
# print("----")
# pull request
temp = self.template_table.copy()
temp['name'] = repo['full_name']
temp = self.get_repository_pull_requests(temp)
self.pull_requests_table.append(temp)
# # forks
# temp = self.template_table.copy()
# temp['name'] = repo['full_name']
# temp = self.get_repository_forks(temp)
# self.forks_table.append(temp)
# # issues_events
# temp = self.template_table.copy()
# temp['name'] = repo['full_name']
# temp = self.get_repository_issues(temp)
# self.issues_table.append(temp)編寫月份分類方法
因為我們的月份分得較死,一時沒想到怎麼封裝,所以寫起來又臭又長。
class github_grab(object):
# ...
def date_classify(self, temp, date_time):
# print(date_time)
if("2021-03-01T00:00:00Z" <= date_time and date_time < "2021-04-01T00:00:00Z"):
temp['2021_03'] += 1
elif("2021-02-01T00:00:00Z" <= date_time and date_time < "2021-03-01T00:00:00Z"):
temp['2021_02'] += 1
elif("2021-01-01T00:00:00Z" <= date_time and date_time < "2021-02-01T00:00:00Z"):
temp['2021_01'] += 1
elif("2020-12-01T00:00:00Z" <= date_time and date_time < "2021-01-01T00:00:00Z"):
temp['2020_12'] += 1
elif("2020-11-01T00:00:00Z" <= date_time and date_time < "2020-12-01T00:00:00Z"):
temp['2020_11'] += 1
elif("2020-10-01T00:00:00Z" <= date_time and date_time < "2020-11-01T00:00:00Z"):
temp['2020_10'] += 1
elif("2020-09-01T00:00:00Z" <= date_time and date_time < "2020-10-01T00:00:00Z"):
temp['2020_09'] += 1
elif("2020-08-01T00:00:00Z" <= date_time and date_time < "2020-09-01T00:00:00Z"):
temp['2020_08'] += 1
elif("2020-07-01T00:00:00Z" <= date_time and date_time < "2020-08-01T00:00:00Z"):
temp['2020_07'] += 1
elif("2020-06-01T00:00:00Z" <= date_time and date_time < "2020-07-01T00:00:00Z"):
temp['2020_06'] += 1
elif("2020-05-01T00:00:00Z" <= date_time and date_time < "2020-06-01T00:00:00Z"):
temp['2020_05'] += 1
elif("2020-04-01T00:00:00Z" <= date_time and date_time < "2020-05-01T00:00:00Z"):
temp['2020_04'] += 1
elif("2020-03-01T00:00:00Z" <= date_time and date_time < "2020-04-01T00:00:00Z"):
temp['2020_03'] += 1
return temp編寫單個 repo 月份 commits 變化
這裡主要就是需要注意要先自己使用 Postman 或是命令指令行試著請求看,檢查回傳的查詢結果的結構,還有時間的判斷,後面的月份變化爬取也是差不多這樣。
class github_grab(object):
# ...
def get_repository_commits(self, commits_temp):
print("start to get " + commits_temp['name'] + " commits\' data")
try:
for i in range(1, 100000):
req = requests.get("https://api.github.com/repos/" + commits_temp['name'] + "/commits?per_page=100&page=" + str(i),
headers=headers, proxies=proxies, timeout=timeoutSec)
if(req.status_code == 403):
print("Rate limit, sleep 60 sec")
time.sleep(60)
i -= 1
continue
elif(req.status_code == 404 or req.status_code == 204):
print('The source is not found')
continue
# print("commits times" + str(i))
items = req.json()
# if no data
if len(items) == 0:
break
# if the time is too older
if(items[0]['commit']['author']['date'] < "2020-03-01T00:00:00Z"):
break
if(items[-1]['commit']['author']['date'] > "2021-04-01T00:00:00Z"):
continue
for date_time in items:
if(date_time['commit']['author']['date'] < "2020-03-01T00:00:00Z"):
break
commits_temp = self.date_classify(
commits_temp, date_time['commit']['author']['date'])
# time.sleep(2)
return commits_temp
except Exception as e:
print(e)
print('fail to get request from ip via proxy')編寫單個 repo 月份 pull requests 變化
class github_grab(object):
# ...
def get_repository_pull_requests(self, pr_temp):
print("start to get " + pr_temp['name'] + " pull requests\' data")
try:
for i in range(1, 100000):
req = requests.get("https://api.github.com/repos/" + pr_temp['name'] + "/pulls?per_page=100&page=" + str(i),
headers=headers, proxies=proxies, timeout=timeoutSec)
if(req.status_code == 403):
print("Rate limit, sleep 60 sec")
time.sleep(60)
i -= 1
continue
elif(req.status_code == 404 or req.status_code == 204):
print('The source is not found')
continue
items = req.json()
# if no data
if len(items) == 0:
break
# if the time is too older
if(items[0]['created_at'] < "2020-03-01T00:00:00Z"):
break
if(items[-1]['created_at'] > "2021-04-01T00:00:00Z"):
continue
for date_time in items:
# print(date_time['created_at'])
if(date_time['created_at'] < "2020-03-01T00:00:00Z"):
break
pr_temp = self.date_classify(
pr_temp, date_time['created_at'])
# time.sleep(2)
return pr_temp
except Exception as e:
print(e)
print('fail to get request from ip via proxy')編寫單個 repo 月份 forks 變化
雖然最後沒有用到這個類方法,但還是將代碼放出來。
class github_grab(object):
# ...
def get_repository_forks(self, forks_temp):
print("start to get " + forks_temp['name'] + " forks\' data")
try:
for i in range(1, 100000):
req = requests.get("https://api.github.com/repos/" + forks_temp['name'] + "/forks?per_page=100&page=" + str(i),
headers=headers, proxies=proxies, timeout=timeoutSec)
if(req.status_code == 403):
print("Rate limit, sleep 60 sec")
time.sleep(60)
i -= 1
continue
elif(req.status_code == 404 or req.status_code == 204):
print('The source is not found')
continue
items = req.json()
# print("forks times" + str(i))
# if no data
if len(items) == 0:
break
# if the time is too older
if(items[0]['created_at'] < "2020-03-01T00:00:00Z"):
break
if(items[-1]['created_at'] > "2021-04-01T00:00:00Z"):
continue
for date_time in items:
# print(date_time['created_at'])
if(date_time['created_at'] < "2020-03-01T00:00:00Z"):
break
forks_temp = self.date_classify(
forks_temp, date_time['created_at'])
# time.sleep(2)
return forks_temp
except Exception as e:
print(e)
print('fail to get request from ip via proxy')編寫單個 repo 月份 issues 變化
class github_grab(object):
# ...
def get_repository_issues(self, issues_temp):
print("start to get " + issues_temp['name'] + " issues\' data")
try:
for i in range(1, 100000):
req = requests.get("https://api.github.com/repos/" + issues_temp['name'] + "/issues/events?per_page=100&page=" + str(i),
headers=headers, proxies=proxies, timeout=timeoutSec)
if(req.status_code == 403):
print("Rate limit, sleep 60 sec")
time.sleep(60)
i -= 1
continue
elif(req.status_code == 404 or req.status_code == 204):
print('The source is not found')
continue
items = req.json()
# if no data
if len(items) == 0:
break
# if the time is too older
if(items[0]['created_at'] < "2020-03-01T00:00:00Z"):
break
if(items[-1]['created_at'] > "2021-04-01T00:00:00Z"):
continue
for date_time in items:
# print(date_time['created_at'])
if(date_time['created_at'] < "2020-03-01T00:00:00Z"):
break
issues_temp = self.date_classify(
issues_temp, date_time['created_at'])
# time.sleep(2)
return issues_temp
except Exception as e:
print(e)
print('fail to get request from ip via proxy')將所有的數據從成 CSV 文件
分別有三個 *.csv 文件,github_basic.csv 是基本的 repo 數據,其它兩個是月變化數據。這裡需要注意的是編碼方式要使用 utf-8,因為 readme 有很多中文字,如果不使用 utf-8,會報存儲錯誤。
def save_all_to_csv(self):
self.save_as_csv("github_basic.csv", self.basic_labels, self.basic_table)
self.save_as_csv("github_commits.csv", self.template_labels, self.commits_table)
self.save_as_csv("github_pull_requests.csv", self.template_labels, self.pull_requests_table)
# self.save_as_csv("github_forks.csv", self.template_labels, self.forks_table)
# self.save_as_csv("github_issues.csv", self.template_labels, self.issues_table)
def save_as_csv(self, fileName, labels, table):
print("\n------------start saving data as csv--------------------------\n")
# save csv
try:
with open(fileName, 'w') as f:
writer = csv.DictWriter(f, fieldnames=labels)
writer.writeheader()
for elem in table:
writer.writerow(elem)
print("save " + fileName + " success")
except IOError:
print("I/O error")編寫 main 函數
if __name__ == "__main__":
github = github_grab()
github.get_all_repositories()
print("repo len " + str(len(github.repositories)))
github.deal_with_repositories()
# print(github.basic_table)
# print(github.commits_table)
# print(github.pull_requests_table)
# print(github.forks_table)
# print(github.issues_table)
github.save_all_to_csv()確認結果
執行文件確認運行結果。
補充
Javascript 的指針問題
因為我在賦值 dict 對象時,發現如果只是普通的用 = 去賦值會導致指針問題,必須使用 dict 對象的 copy() 方法。
temp = self.template_table.copy()結語
這次的機器學習與數據挖掘的實驗我負責爬蟲的部分,由於一開始我沒有爬月變化的數據特徵,所以導致全組都在等我重新爬取新的數據,也在合作過程中發現自己的缺失,這次的工作分配讓我學到很多數據爬取的技巧,感謝大家的分工合作,最後完成了小組項目。